意圖分析, 表示 ⇒ 輸入文字敘述, 要分類文字屬於何種意圖
sample:
"i dont like my current insurance plan and want a new one" ⇒ insurance_change
"when will my american express credit card expire" ⇒ expiration_date
“how would i get to city hall via bus” ⇒ directions
題意: 輸入文字敘述, 分類文字屬於何種意圖
要完成一個程式, 我想第一步應該是釐清這支程式的抽象, 先定義清楚我們究竟要完成什麼
所以我畫了下面這張圖

可以得知我們的目標是訓練出這樣的 AI 模型
訓練資料連結:
https://github.com/leon123858/ADL2022/tree/main/HW1/data/intent
接著就可以回頭看看我們的訓練資料來從頭想想, 我們該如何完成訓練
打開訓練資料如下
[
{
"text": "how long should i cook steak for",
"intent": "cook_time",
"id": "eval-0"
},
{
"text": "please tell me how much money i have in my bank accounts",
"intent": "balance",
"id": "eval-1"
},
{
"text": "what is the gas level in my gas tank",
"intent": "gas",
"id": "eval-2"
},
...
]
可以看見每個句子都被分類到對應的某種意圖(即為分類)
此時我們可以透過簡單的 python 腳本大概去了解總共有幾種意圖
"""load json and check intent count"""
import json
with open('./train.json', encoding='utf8') as f:
data = json.load(f)
intent_set = set()
for item in data:
intent_set.add(item['intent'])
print(len(intent_set)) # 150
自此, 對整個模型的樣貌, 我們有了更清晰明確的認識, 如下圖, 其中句子在150個分類中各自的機率可以用長度為150的數字陣列來表示

因為實務上文字無法直接輸入模型, 所以我們要用 text encoding 這類的演算法把文字轉換成數字, 畢竟 AI 的本質就是一個超大型“矩陣”, 模型的推測其實就是矩陣運算的結果, 模型的訓練其實就是矩陣參數的調適, 基於以上理解, 畫出以下更明確設計圖

該有的流程都清楚後我們就來開始寫程式一步一步把這個 AI 任務完成吧!
提出如何手刻模型前我想先試著以我自己的理解來聊聊這項任務的本質, 希望可以協助讀者後續的理解, 解釋過程做了大量的簡化, 只是為了協助理解, 有些細節不是特別合理
首先要有一個概念 AI 模型的本質其實就是連續互相乘法加法的多個超大型矩陣, 所謂的參數數量其實就是這些矩陣內部的元素, 所以不管要完成的任務有多困難, 本質上我們都是在試著創建出一個函數, 在給定特定的輸入後取得我們想要的輸出, 因為參數的數量極大(函數極為複雜), 所以這個函數理論上可以解決所有問題。
回到實務面來說, 我們必須要有一種標準化的邏輯來調整函數內的參數, 這就是我們所說的訓練模型
最簡單的訓練方法就是把輸入丟到函數中查看輸出, 如果輸出不對, 那就隨機調整函數(模型)內的參數, 調整到某一組隨機參數可以在所有已知的輸入下輸出對應的輸出, 以下舉一個簡單的例子
假設我們想要訓練一個簡單的模型可以輸入兩個整數, 輸出對應的加法結果, 那我們可以創建一個模型(矩陣)如下, 僅有 2 個參數

當輸入兩個整數 5,7 答案明顯是錯的
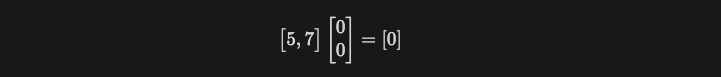
但此時如果好死不死, 剛好隨機出 1, 1 這組參數
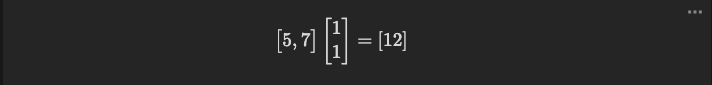
之後這種兩數字加法的 task 都可以正確地完成了
當然以上的方法有很大的問題就是當參數足夠多時, 隨機出正確參數的可能性極低, 所以我們必須要有一種方法可以協助我們微調參數, 可以使我們每一次的訓練都能更接近正確的參數一點
這邊就用到 Loss function 和 optimizer 的概念
loss function 有很多變形, 但最基本的概念就是評價當前的答案和正確答案有多少落差, 以上方的範例來說, 我們可以定義 loss function 是 真實答案-輸出 的值, 如此當答案正確時 loss 為 0, 答案差很多時 loss 很大
optimizer 可以說成是一種調參的工具, 可以根據 loss 值來決定各個參數要怎麼調整
回到上面的例子, 我們可以定義 optimizer 是把 loss * 0.1 隨機加到上下任一個參數
所以就會有以下的訓練過程:
可以發現 loss 很明確地不斷下降, 要是多幾組訓練資料, 很快就可以產生一組類似 1, 1 的參數了
接著觀察上面的訓練過程, 可以發現隨著 loss 的下降, optimizer 的策略好像開始不合時宜, 當 loss 已經很接近 0 時, 直接把 loss 乘 0.1 隨機加好像太多了, 這時就有了 scheduler 的用武之地
scheduler 可以在給定的條件下微調 optimizer 的優化參數, 例如當訓練 10 次後改成 loss * 0.05 之類
以上我們描述了幾個重要的概念 包含: model , loss function , optimizer, scheduler
他們都是每一筆資料訓練過程中的重要組成, 接著人類開始思考一次一筆資料訓練會不會太慢, 於是衍伸出了 dataset , dataLoader 的概念
dataset 把資料整理成一筆一筆的形式, dataLoader 把資料多筆結合成一組, 用一組一組的形式來訓練, 這邊一組資料, 我們喜歡用 batch 稱呼, 用上面做範例
dataset 可以整理出這樣的東西
dataLoader 若把一組 (batch) 設為 2 筆資料, 可以整理出這樣的輸出
如此一來 optimizer 可以計算一個 batch 的 loss 總和, 再統一調整, 如此一來因為可以平行化, 也減少調整次數, 訓練速度自然提升
最終, 我們利用上方提到的概念, 撰寫一個偽代碼來完成這個 Intent Classification 的任務
src code:
https://github.com/leon123858/ADL2022/blob/main/HW2/src/bonus/train_intent.ipynb
可以把上方程式碼貼至 google colab 即可順利運行, 記得把壓縮過後的資料放在相同目錄中喔
以下一格格解釋做了什麼
首先下載相依套件
!pip3 install http://download.pytorch.org/whl/cu80/torch-0.3.0.post4-cp36-cp36m-linux_x86_64.whl
!pip3 install torchvision
!pip3 install pickle
!pip3 install datasets
!pip3 install transformers
其中 torch 是來自 pytorch https://pytorch.org/
是完成 AI 運算的底層模型
datasets 則是專門拿來加載資料的組件
transformers 則是對 pytorch 的封裝 ,讓我們可以直接從抽象層完成模型的訓練, 不用理解模型底層的架構
接著解壓縮訓練資料, 上方連結有提供, 可以壓縮後上傳 colab
from zipfile import ZipFile
file_name = "intent.zip"
with ZipFile(file_name, 'r') as zip:
zip.extractall()
print('Done')
利用 datasets 加載訓練用資料
from datasets import load_dataset
data_files = {}
extension = ""
data_files["train"] = "intent/train.json"
data_files["eval"] = "intent/eval.json"
extension = "intent/train.json".split(".")[-1]
datasets = load_dataset(
extension,
data_files=data_files
)
把資料整理成要的格式存好
# 訓練時輸入的句子
train_texts = [item["text"] for item in datasets["train"]]
# 訓練時輸入的句子對應的意圖
train_labels = [item["intent"] for item in datasets["train"]]
dev_texts = [item["text"] for item in datasets["eval"]]
dev_labels = [item["intent"] for item in datasets["eval"]]
# 所有可能的句子分類(意圖)
labels = list(set(train_labels))
len(labels) # 150 種意圖
# 意圖的編號與返身
idx2label = labels
label2idx = {k:idx for idx,k in enumerate(labels)}
創建資料集提供訓練
以下是 pytorch 的標準用法, 需要繼承以及 overwrite 下面這三種方法
以下分別描述個要做什麼
import torch
# 訓練時從中取出訓練用資料以及對應的答案
class ClassificationDataset(torch.utils.data.Dataset):
# 實作下兩個方法時所需要的變數, 參數:訓練的句子們,句子的類別們
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
# 返回一筆資料(一個樣本), 含:句子的陣列, 句子的類別
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['label'] = label2idx[self.labels[idx]]
return item
# 類別個數
def __len__(self):
return len(self.labels)
正確率計算函數
訓練時透過模型可以推算在 150 個分類中的機率, 取出最高的比較是否和答案相符合
from sklearn.metrics import accuracy_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
acc = accuracy_score(labels, preds)
return {
'accuracy': acc
}
開始訓練
from transformers import AutoTokenizer, Trainer, TrainingArguments, AutoModelForSequenceClassification
# 要用哪一種模型, 可以到 https://huggingface.co/ 找
model_ids = ["prajjwal1/bert-tiny"]
accuracies = []
for model_id in model_ids:
print(f"*** {model_id} ***")
# 創建 encoder
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 創建模型(引用別人已經完成的模型)
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=len(labels))
# 利用 encoder 編碼輸入文字成為數字陣列(向量)
train_texts_encoded = tokenizer(train_texts, padding=True, truncation=True, return_tensors="pt")
dev_texts_encoded = tokenizer(dev_texts, padding=True, truncation=True, return_tensors="pt")
# 把編碼結果作成資料集訓練要用
train_dataset = ClassificationDataset(train_texts_encoded, train_labels)
dev_dataset = ClassificationDataset(dev_texts_encoded, dev_labels)
# 設置訓練參數, 可查看 https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=8,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=int(len(train_dataset)/16),
weight_decay=0.01,
logging_dir='./logs',
evaluation_strategy="steps",
eval_steps=50,
save_steps=50,
save_total_limit=10,
load_best_model_at_end=True,
no_cuda=False
)
# 開始訓練
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=dev_dataset,
)
trainer.train()
如此即可順利完成系統, 得出語句意圖
# 取得預測結果
test_results = trainer.evaluate(test_dataset)
# 正確率
test_results["eval_accuracy"]
按照前方 datasets 的用法, 放入想要預測的資料(假設叫 test_dataset), 用上方這句可以產生預測結果
總有些人會覺得全部都調用套件沒有辦法真正理解自己做了什麼, 以下提供給那些想要挑戰自我的人
source code:
https://github.com/leon123858/ADL2022/tree/main/HW1
可以先直接試跑
# 下載預訓練模型
bash download_glove.sh
# 準備輸入資料的編碼以及 encoder
python preprocess_intent.py
**#** 訓練
****python train_intent.py --recover=True --hidden_size=512 --schedule=0.5 --num_epoch=15 --batch_size=64 --lr=1e-5 --dropout=0.1 --num_layers=3
**#** 預測
****python test_intent.py --test_file './data/intent/test.json' --ckpt_path ckpt/intent/best.pt --pred_file 'pred.intent.csv' --num_layers=3 --hidden_size=512"
在 download_glove 中我下載了來自 https://nlp.stanford.edu/projects/glove/ 的訓練結果
詳細的原理可以自行查閱
在 preprocess_intent 中我統整了所有輸入的句子中出現的詞彙以及意圖, 最後再把 glove 的下載結果瘦身成剛好我會遇到的詞彙並且打包成一個 encoder
在 train_intent 中我引用了自定義的 dataset / model 完成了訓練
值得一提的是自定義 modal 的寫法
因為是語言模型, 在模型最前面加了一層外部的 encoder 來把文字編碼
# 繼承 torch.nn.Module
class SeqClassifier(torch.nn.Module):
def __init__(
self,
embeddings: torch.tensor,
hidden_size: int,
num_layers: int,
dropout: float,
bidirectional: bool,
num_class: int,
) -> None:
super(SeqClassifier, self).__init__()
# 加載外部的 encoder 作為模型的其中一層
self.embed = Embedding.from_pretrained(embeddings, freeze=False)
# 利用 RNN 運算每個句子
self.rnn = RNN(input_size=self.embed.embedding_dim, hidden_size=hidden_size, num_layers=num_layers,
nonlinearity='relu', dropout=dropout, bidirectional=bidirectional, batch_first=True)
# 最後添加線性層, 把輸出矩陣轉換成長度 150 的向量
self.out_layer = Linear(
hidden_size*(2 if bidirectional == True else 1), num_class)
# 定義每筆數據的運算, 多個矩陣的乘法, 重點在維度要對好
def forward(self, batch, IS_MPS=False) -> Dict[str, torch.Tensor]:
# TODO: implement model forward
data = batch['data'].clone().to('mps' if IS_MPS else 'cpu')
# dim above: batch_size * string_len
embed_out = self.embed(data)
# dim above: batch_size * string_len * word_vector_len
rnn_out, _ = self.rnn(embed_out)
# dim above: batch_size * string_len * hidden_size * (2 if 雙向)
encode_out = torch.mean(rnn_out, 1)
# dim above: batch_size * hidden_size * (2 if 雙向)
final_out = self.out_layer(encode_out)
# dim above: batch_size * num_class
return final_out
版大您好,小弟我照著上面的簡易版本進行,把三個json檔存起來丟到colab,複製程式碼作執行,前面都很順利,能夠執行到100趴跑完,但是最後出現了一個錯誤NameError: name 'test_dataset' is not defined,想問一下這個錯誤應該如何處理,謝謝!
抱歉, 為筆誤, 這兩行應該刪掉, 作用分別如註釋
# 取得預測結果
test_results = trainer.evaluate(test_dataset)
# 正確率
test_results["eval_accuracy"]
刪掉的原因是我在 sample code 中並沒有準備預測數劇集, 所以不能算預測正確率, 如果要使用, 自己額外切一些訓練資料出來, 按照 sample code 引用數據的方法做出 test_dataset 即可
謝謝版大解釋!
 leon123858
leon123858
